Como Criar Gráficos de Caixa (Box Plots) com Python?
Recentemente, trabalhando em um projeto de meta-análises para um artigo em fisiologia vegetal, me deparei com a necessidade de criar uma visualização de dados que resumisse a distribuição de concentrações de um sal qualquer utilizadas para avaliar o stress salino em diferentes espécies. Intuitivamente pensei em gráficos de barra.
Afinal, gráficos de barra são ótimos para comparar médias entre grupos. Certo?
Errado! Ou melhor, nem sempre! Embora os gráficos de barra permitam comparar médias entre grupos, eles escondem informações muito importantes sobre a distribuição dos dados: variabilidade, discrepâncias, assimetrias, etc.
Para o meu caso, comparar médias não seria suficiente. Precisávamos entender como as concentrações salinas variavam dentro de cada grupo de espécies estudadas. Foi aí que os gráficos de caixa se mostraram a ferramenta perfeita!
E como sou um adepto da cobrinha programadora, este tutorial guiará você na criação de gráficos de caixa em Python usando duas bibliotecas populares: matplotlib e seaborn.
Pré-requisitos
- Python instalado.
- Compreensão básica de
listasearraysNumPy. - Alguma familiaridade com
DataFramesdo Pandas. - Bibliotecas instaladas. Se não as tiver, abra seu terminal ou prompt de comando e execute:
pip3 install matplotlib numpy pandas seaborn
O que é um Gráfico de Caixa?
Um gráfico de caixa (ou box plot / gráfico de caixa e bigodes) exibe o “resumo de cinco indicadores” de um conjunto de dados:
- Mínimo: O menor ponto de dados (excluindo outliers). Representado geralmente pelo fim do “bigode” inferior.
- Primeiro Quartil (Q1): O valor abaixo do qual 25% dos dados se encontram. É a borda inferior da caixa.
- Mediana (Q2): O valor central do conjunto de dados (percentil 50). É a linha dentro da caixa.
- Terceiro Quartil (Q3): O valor abaixo do qual 75% dos dados se encontram. É a borda superior da caixa.
- Máximo: O maior ponto de dados (excluindo outliers). Representado geralmente pelo fim do “bigode” superior.
E mais!
- Intervalo Interquartil (IIQ ou IQR): A diferença entre Q3 e Q1 (
IIQ = Q3 - Q1). Representa os 50% centrais dos dados (a altura da caixa). - “Bigodes” (Whiskers): Linhas que se estendem da caixa e mostram a maioria da variação dos dados.
- Outliers (Valores Discrepantes): Pontos de dados que caem fora dos limites dos bigodes. São frequentemente plotados individualmente.
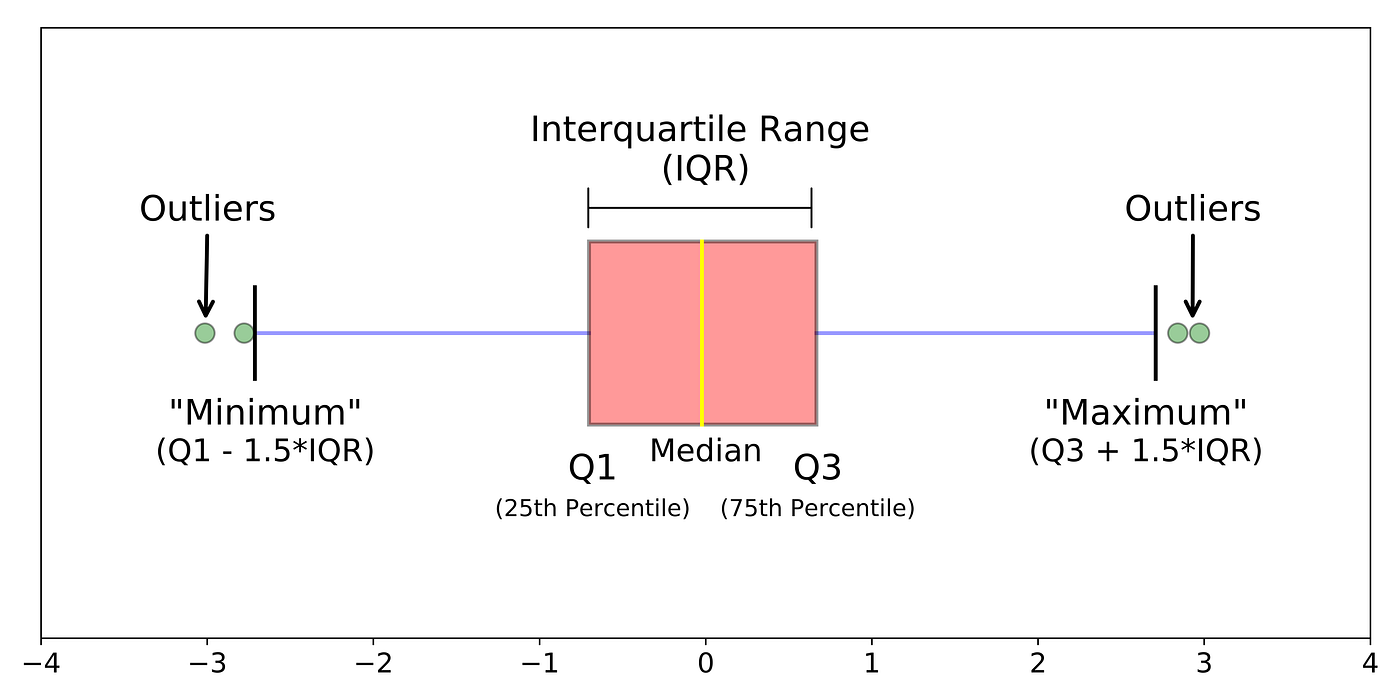 (Fonte da Imagem: Towards Data Science / Michael Galarnyk)
(Fonte da Imagem: Towards Data Science / Michael Galarnyk)
Preparando o Ambiente e os Dados
Antes de plotar, precisamos preparar nosso ambiente importando as bibliotecas e criando os dados de exemplo que usaremos ao longo do tutorial.
1. Importando as Bibliotecas
Vamos começar importando as ferramentas necessárias.
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import seaborn as sns
# Define um estilo visual padrão para os gráficos (opcional)
sns.set_theme(style="ticks") # Para dar um visual mais agradável ao nosso gráfico!Esta primeira parte é como apresentar as ferramentas que vamos usar. Imagine que você vai cozinhar: precisa pegar as panelas, os utensílios, etc. Aqui, estamos “importando” bibliotecas, que são conjuntos de funções e recursos prontos para usar.
matplotlib.pyplot as plt: Esta é a biblioteca principal para criar gráficos em Python. Usamos o apelidopltpara facilitar a escrita depois (digitamospltem vez dematplotlib.pyplot).numpy as np: NumPy é uma biblioteca para trabalhar com números, especialmente listas e tabelas de números (arrays). Ela nos ajuda a gerar dados aleatórios e fazer cálculos matemáticos.pandas as pd: Pandas é uma biblioteca poderosa para trabalhar com dados organizados em tabelas, como planilhas. Ela introduz um tipo de dado chamado “DataFrame” que é super útil.seaborn as sns: Seaborn é uma biblioteca construída sobre o Matplotlib, que deixa os gráficos mais bonitos e fáceis de criar, especialmente quando trabalhamos com DataFrames do Pandas.
2. Criando Dados de Exemplo
Como os dados reais farão parte de um artigo, e como este artigo ainda não foi publicado, vamos criar um conjunto de dados fictício para ilustrar o uso dos gráficos de caixa. Para isso, usaremos o NumPy para gerar dados aleatórios. Vamos criar um DataFrame com cinco espécies e suas respectivas concentrações salinas.
Definindo a Semente Aleatória (Para Reprodutibilidade): Para que você obtenha os mesmos resultados que eu ao executar este código, definimos uma “semente” para o gerador de números aleatórios.
np.random.seed(12210)A geração de números aleatórios em computadores é feita por algoritmos determinísticos, o que significa que eles produzem sequências de números que parecem aleatórias, mas são totalmente previsíveis se você souber o ponto de partida. Nesse caso, a nossa semente.
Definindo Parâmetros da Simulação: Criamos uma lista de espécies e um dicionário com parâmetros (média loc e desvio padrão scale) para simular diferentes tolerâncias ao sal. Lembrete: são dados fictícios!
nomes_especies = ['Arroz', 'Milho', 'Tomate', 'Trigo', 'Cevada']
parametros = {
'Arroz': {'loc': 80, 'scale': 40},
'Milho': {'loc': 120, 'scale': 50},
'Tomate': {'loc': 180, 'scale': 60},
'Trigo': {'loc': 250, 'scale': 50},
'Cevada': {'loc': 300, 'scale': 70}
}
num_amostras = 10 # Número de "experimentos" simulados por espécieGerando e Estruturando os Dados: Agora, usamos um loop para gerar os dados para cada espécie, arredondando para múltiplos de 20 e garantindo que fiquem entre 20 e 400. Armazenamos tudo em listas.
lista_concentracoes = []
lista_especies_col = []
for especie in nomes_especies:
# Gera concentrações contínuas
concentracoes_raw = np.random.normal(
loc=parametros[especie]['loc'],
scale=parametros[especie]['scale'],
size=num_amostras
)
# Arredonda para múltiplo de 20
concentracoes_arredondadas = np.round(concentracoes_raw / 20.0) * 20.0
# Limita o intervalo
concentracoes_clipped = np.clip(concentracoes_arredondadas, 20, 400)
# Adiciona às listas
lista_concentracoes.extend(concentracoes_clipped)
lista_especies_col.extend([especie] * num_amostras)O loop for especie in nomes_especies itera sobre cada nome de espécie na lista nomes_especies.
Em seguida, para cada espécie, geramos um conjunto de dados de concentrações salinas usando a função np.random.normal(), que cria números aleatórios seguindo uma distribuição normal.
Essas concentrações são então arredondadas para o múltiplo de 20 mais próximo e limitadas entre 20 e 400 usando np.clip(). Isso garante que os dados estejam num intervalo específico.
Criando o DataFrame: Finalmente, organizamos essas listas em um DataFrame do Pandas, que é a estrutura ideal para trabalhar com dados tabulares em Python.
df_plantas = pd.DataFrame({
'Especie': lista_especies_col,
'Concentracao_Sal': lista_concentracoes
})
# Verificando os dados (opcional, mas recomendado)
print("DataFrame Criado (Primeiras 5 linhas):")
print(df_plantas.head())
print("\nEstatísticas Descritivas por Espécie:")
print(df_plantas.groupby('Especie')['Concentracao_Sal'].describe())DataFrames são estruturas de dados tabulares, como planilhas, e são muito poderosos para análise de dados. Criamos um DataFrame chamado df_plantas com duas colunas:
'Especie': Contém os nomes das espécies.'Concentracao_Sal': Contém as concentrações salinas correspondentes.
Visualizando uma Única Espécie (com Matplotlib)
Vamos começar criando um gráfico de caixa apenas para a espécie “Arroz” usando a biblioteca Matplotlib. Isso nos ajuda a entender os passos básicos.
1. Filtrando os Dados
Primeiro, selecionamos apenas os dados referentes ao Arroz do nosso DataFrame principal.
df_arroz = df_plantas[df_plantas['Especie'] == 'Arroz']2. Criando a Figura e o Gráfico
Criamos a “tela” (figura) e os “eixos” onde o gráfico será desenhado. Pense na figura como uma tela em branco e os eixos como as linhas que definem onde você vai desenhar. Então usamos ax.boxplot() para criar o gráfico de caixa.
# Cria a figura e os eixos
fig, ax = plt.subplots(figsize=(8, 6)) # Define o tamanho da figura
# Cria o gráfico de caixa para os dados de Arroz
# patch_artist=True preenche a caixa com cor
ax.boxplot(df_arroz['Concentracao_Sal'], patch_artist=True)3. Personalizando o Gráfico
Adicionamos título, rótulos e ajustamos os eixos para melhor clareza.
# Adiciona título e rótulos
ax.set_title('Gráfico de Caixa - Concentração Salina (Arroz)')
ax.set_ylabel('Concentração Salina (mM)')
ax.set_xticklabels(['Arroz']) # Define o rótulo no eixo X
# Ajusta os limites e marcas do eixo Y
ax.set_ylim(bottom=0, top=220) # Define limite inferior e superior
ax.set_yticks(np.arange(0, 220, 20)) # Define as marcas de 20 em 20
# Adiciona uma grade horizontal
ax.grid(axis='y', linestyle='--', alpha=0.7) # Linhas pontilhadas com transparência4. Exibindo o Gráfico
Finalmente, mostramos o gráfico.
plt.show()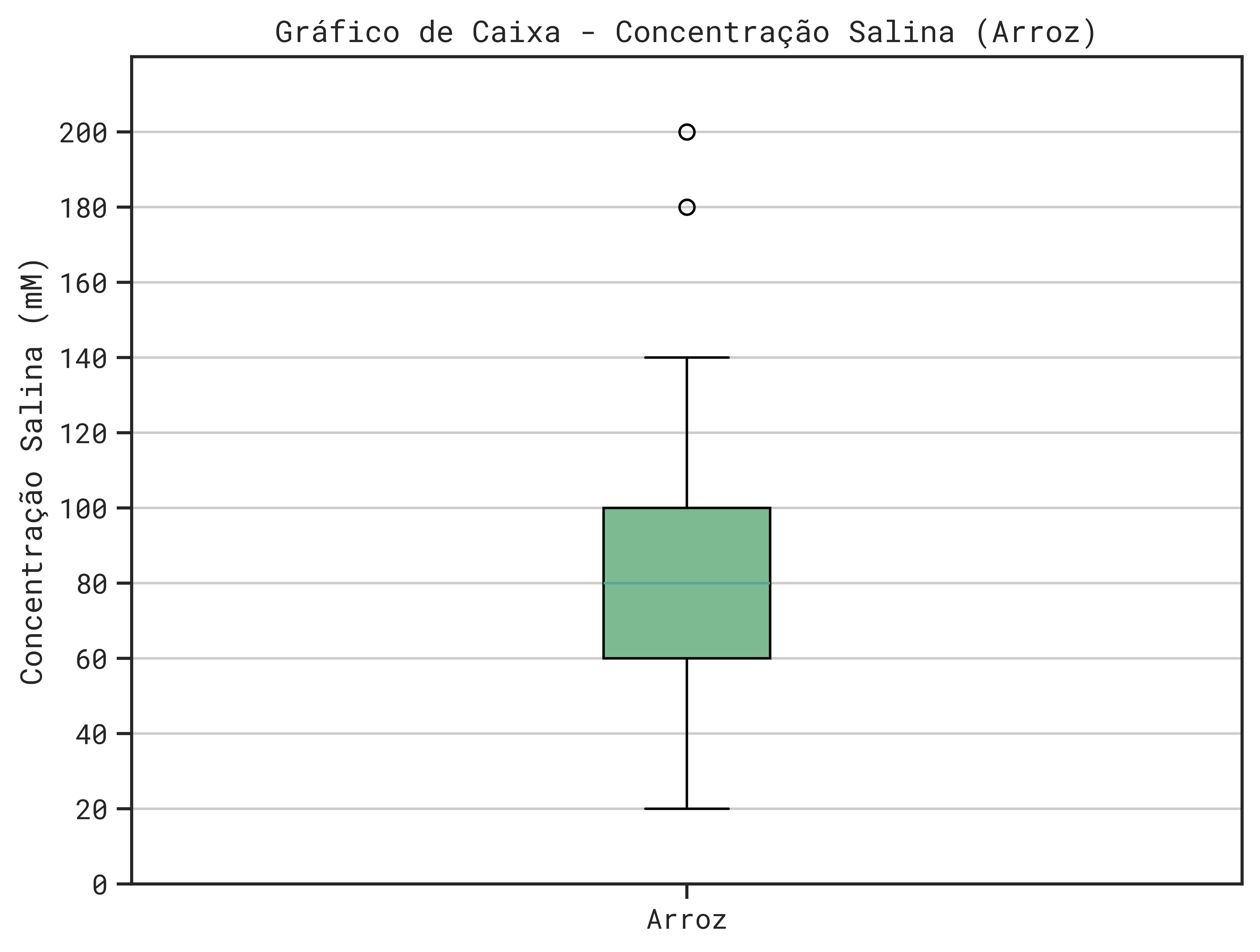
5. Interpretando o Gráfico do Arroz
- Caixa Verde
- Primeiro Quartil - Q1 (
Borda Inferior): Localizada em 60 mM. Isso significa que 25% das amostras de concentração salina para o Arroz estão em 60 mM ou menos. - Terceiro Quartil - Q3 (
Borda Superior): Localizada em 100 mM. Isso indica que 75% das amostras de concentração salina estão em 100 mM ou menos. - Mediana - Q2 (
Linha Dentro da Caixa): Localizada em 80 mM. A mediana é o valor central, ou seja, 50% das amostras estão abaixo deste valor e 50% estão acima. - Intervalo Interquartil (IIQ) (
altura da caixa)`: representa o intervalo interquartil, obtido por Q3 - Q1 = 100 mM - 60 mM = 40 mM. Este intervalo contém os 50% centrais dos dados.
- Primeiro Quartil - Q1 (
- Bigodes
- Bigode Inferior: Estende-se da borda inferior da caixa até 20 mM. Isso indica que o menor valor de concentração salina numa faixa “normal” é 20 mM.
- Bigode Superior: Vai da borda superior da caixa até 140 mM. Isso indica que o maior valor de concentração salina numa faixa “normal” é 140 mM.
- Outliers
- Há dois círculos acima do bigode superior, em 180 mM e 200 mM. Estes são outliers, ou seja, valores que estão significativamente distantes da maior parte dos dados. Eles representam concentrações salinas que foram consideradas “excepcionalmente altas”.
Comparando Todas as Espécies com Seaborn
Ok, conseguimos um belo gráfico de caixa para observar os dados experimentais para a espécie Arroz. Mas e as outras? Comparar a tolerância ao sal entre diferentes espécies é ainda mais interessante.
Para facilmente plotar as distribuições de concentração salina para todas as espécies em um único gráfico, vamos utilizar a função sns.boxplot() do Seaborn. O Seaborn, como vimos, é construído sobre o Matplotlib e oferece uma maneira mais concisa e elegante de criar gráficos estatísticos, especialmente quando trabalhamos com DataFrames do Pandas.
1. Criando o Gráfico Comparativo
Usamos sns.boxplot(), especificando as colunas do DataFrame para os eixos x e y.
# Cria uma nova figura e eixos para o gráfico comparativo
fig, ax = plt.subplots(figsize=(10, 7)) # Um pouco maior para caberem as 5 caixas
# Cria o gráfico de caixa comparativo usando Seaborn
sns.boxplot(
x='Especie', # Nome exato da coluna para os grupos no eixo X
y='Concentracao_Sal', # Nome exato da coluna para os valores no eixo Y
data=df_plantas, # O DataFrame com os dados
ax=ax, # Especifica em quais eixos desenhar
palette='Pastel1', # Define uma paleta de cores (opcional)
hue='Especie', # Colore cada caixa de acordo com a espécie (opcional, mas útil)
legend=False # Remove a legenda automática do 'hue' se não for necessária
)
# Adiciona título e rótulos (ajustados para o gráfico comparativo)
ax.set_title('Comparação da Concentração Salina por Espécie')
ax.set_xlabel('Espécie Vegetal') # Rótulo mais genérico para o eixo X
ax.set_ylabel('Concentração Salina (mM)')
# Adiciona grade horizontal (opcional)
ax.grid(axis='y', linestyle='--', alpha=0.7)
# Exibe o gráfico
plt.show()Como sns.boxplot funciona aqui?
x='Especie': Mapeia a coluna ‘Especie’ para o eixo X, criando uma caixa para cada espécie única.y='Concentracao_Sal': Mapeia a coluna ‘Concentracao_Sal’ para o eixo Y, mostrando a distribuição desses valores.data=df_plantas: Indica que os dados vêm do nosso DataFramedf_plantas.ax=ax: Diz ao Seaborn para desenhar o gráfico nos eixos que criamos complt.subplots().palette='tab10': (Opcional) Aplica um esquema de cores pré-definido. Existem muitas paletas disponíveis no Seaborn!hue='Especie': (Opcional) Colore cada caixa com base na espécie. Como já estamos separando por espécie no eixo X, isso serve principalmente para adicionar cor.legend=Falseesconde a legenda que ohuecriaria automaticamente, pois os rótulos já estão no eixo X.
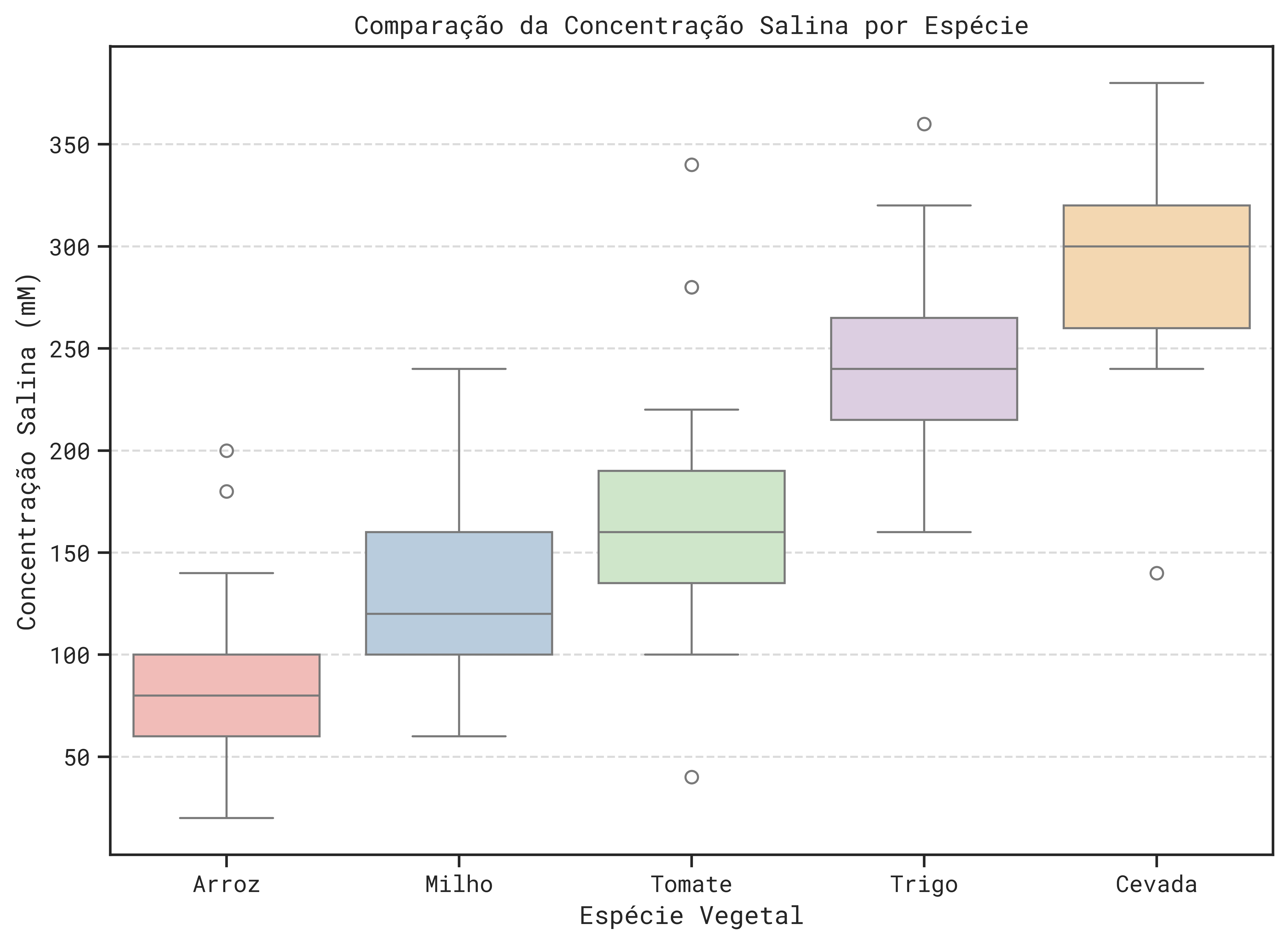
2. Interpretando o Gráfico Comparativo
Como podemos ver, o gráfico compara como as cinco espécies de plantas são estudadas em diferentes concentrações de sal. Cada “caixinha” representa uma espécie.
Tolerância Média (Linha do Meio - Mediana): Veja como a linha do meio sobe da esquerda para a direita. O Arroz tem a linha mais baixa (80 mM), enquanto a Cevada tem a mais alta (280 mM). Conclusão Simples: em média, estudos com Cevada utilizam uma concentração de sal maior, diferente de estudos com Arroz.
Variação nos Resultados (Tamanho da Caixa e Bigodes): Olhe o tamanho total da caixa e dos bigodes. Caixas maiores e bigodes mais longos = mais variação. Milho e Cevada têm caixas e bigodes maiores, indicando que os resultados para elas foram mais “espalhados”. Arroz e Tomate parecem mais “consistentes” (caixas e bigodes menores). Conclusão Simples: A concentração de sal variou mais para Milho e Cevada.
Resultados Atípicos (Bolinhas Fora - Outliers): Algumas espécies têm bolinhas fora dos bigodes (ex: Arroz, Tomate, Trigo, Cevada). Conclusão Simples: Isso mostra que, ocasionalmente, houve resultados bem diferentes do padrão normal para algumas plantas.
É muito mais informativo que apenas comparar médias, pois vemos a distribuição completa para cada espécie!
Os gráficos de caixa são ferramentas visuais incrivelmente úteis para explorar e comparar distribuições de dados, revelando muito mais do que simples médias. Neste tutorial, vimos como:
- Preparar dados simulados usando NumPy e organizá-los em um DataFrame do Pandas.
- Criar um gráfico de caixa para um único grupo usando Matplotlib.
- Interpretar os componentes de um gráfico de caixa.
- Utilizar o Seaborn para comparar facilmente múltiplos grupos diretamente de um DataFrame.
Seja analisando dados de fisiologia vegetal ou qualquer outro tipo de dado numérico, considere usar gráficos de caixa para obter uma compreensão mais profunda da variabilidade e das características dos seus dados!